- Free OGG to MP3 Converter
- Free FLV to AVI Converter
- Free WMA to MP3 Converter
- Free MP3 To Wave Converter
- Free RM to MP3 Converter
- Free Mario Game
- Free XLS Viewer
- Free WAV to MP3 Converter
- Free Aquarium Screensaver
- Free DVDFab Decrypter
- Free Mobile 3GP converter
- Free PDF to Flash Converter
- Free MP4 to AVI Converter
- Free PDF to Word Converter
- Free MP3 to WAV Converter
- Free File List
- Free FLV to MP3 Converter
- Free Wallpaper Changer
- Free DVD to MPEG Converter
- Free Doc Convertor
- Free Audio Editor
- Free Video to WMV Converter
- Free YouTube to FLV Converter
- Free MP3 Editor
- Free Video to MP3 Converter
- Free PDF Creator
- Free Sound Recorder
- Free AMR to MP3 Converter
- Free MOV to AVI Converter
- Free DivX Converter
- Free Wave To MP3 Converter
- Free Aquarium Screensaver
- Free XLS Viewer
- Free PDF to Word Converter
- DriverHub
- Your Link Here
- This site for sale
- Free HD Video Converter Factory
- WonderFox DVD Ripper Speedy 13.
- Vartika Zimbra to PST Converter
- Free Android Data Recovery 1.1.
- Aiseesoft Video to GIF Converte
- Google Selection Search 1.0
- Apeaksoft Free HEIC Converter 1
- Best PDF to Word Converter 3.5
- MSG Files Without Email Client
- DriverHub 1.1.2
- MSG Viewer Freeware 4.0
- Read PST File Opener Free Downl
- Free Download EML File Reader T
- Easy Photo Studio Free for Wind
- Easy Photo Studio Free for Mac
- PST File Reader Without Outlook
- Free YouTube to FLV Converter
- Free MP3 Editor
- Free Video to MP3 Converter
- Free PDF Creator
- Free Sound Recorder
- Free AMR to MP3 Converter
- Free MOV to AVI Converter
- Free DivX Converter
- Free Wave To MP3 Converter
- Free Aquarium Screensaver
- Free XLS Viewer
- Free PDF to Word Converter
- DriverHub
- Your Link Here
- This site for sale
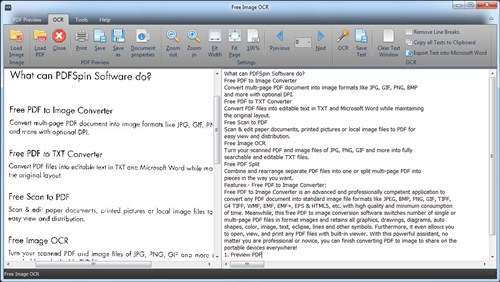
Download free program Free Image OCR 7.2.6 for free
Free Image OCR allows the possibility to recognize the text contained within any scanned document or image and can make
Free Image OCR allows the possibility to recognize the text contained within any scanned document or image and can make it fully selectable, searchable and editable. When the documents with which you usually work are in scanned PDF or image format, you can always resort to Free Image OCR to carry out these processes. Free Image OCR has a very quick optical recognition engine, and allows the possibility to convert any PDF into a text document without problems. The produce is reduced to the simple fact of opening the PDF documents and then clicking on OCR. Our new technology using mega pixel cameras to digitize books and newspapers generates high quality preservation images, which greatly increases OCR accuracy.
Free Image OCR is designed with a text editor which allows you to edit the OCR result text without MS Word. In text window, you are allowed to add or correct text. In addition, it is available to use editing tools to clear text, remove line breaks, copy all texts to clipboard and export text into MS word for other usages. Free Image OCR saves you much time and money by sharing electronic documents instead of stacks of paper files.
Free Image OCR integrates preview functionality for users to open, view, and print any PDF documents on windows operating systems with preview panel. At the same time, some metadata information like title, author, subject, etc. can be added to your PDF files to complete your PDF properties and identify your PDF document in search results. Through the PDF previewer, you may preview any of your PDF files with support for zoom in/out and Fit Width/Height/Page or switch between pages with First, Previous, Next and Last buttons.
Free Image OCR supports almost all kinds of image formats like JPG/JPEG, TIF, TIFF, BMP, GIF, PNG, EMF, WMF, JPE, ICO, JFIF, PCX, PSD, PCD, TGA and many more. Any text within images and PDF files can be output to plain text formats or MS Word.